Présentation sans titre.pptx
•Download as PPTX, PDF•
0 likes•6 views

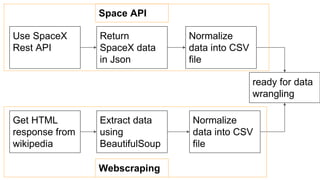
1. The document discusses scraping SpaceX data from Wikipedia using the Beautiful Soup library and normalizing it into a CSV file for data wrangling. 2. Key steps include getting an HTML response from Wikipedia, extracting the data using Beautiful Soup, and normalizing it into a CSV file. 3. The normalized CSV file is then ready for data wrangling tasks like cleaning, filtering, and calculating metrics from the SpaceX launch data.
Report
Share
Report
Share

Recommended
Florence Spacex Final Presentation DS Capstone.pdf
Coursera IBM Applied Data Science Capstone SpaceX project final presentation
Github link for reference: https://github.com/florenceyyw/Applied-Data-Science-Capstone
IBM SpaceX Capstone Project
In this project, I will work in SpaceX company and try to predict the Falcon 9 first stage. It’s important to know if the rockets will land successfully or not because the failure will cost the company many resources.
Kafka Summit NYC 2017 - Singe Message Transforms are not the Transformations ...
Single message transformations allow lightweight modifications to individual messages as they are ingested or emitted by Kafka Connect connectors. Some key uses of single message transformations include data masking, event routing, event enhancement, and partitioning. They involve simple, message-at-a-time transformations configured through properties rather than writing complex code. Kafka Streams is better suited for more complex transformations like aggregations, joins, and windowing where the transformed data is stored back in Kafka.
#29.스프링프레임워크 & 마이바티스 (Spring Framework, MyBatis)_스프링프레임워크 강좌, 재직자환급교육,실업자국비지원...
#29.스프링프레임워크 & 마이바티스 (Spring Framework, MyBatis)_스프링프레임워크 강좌, 재직자환급교육,실업자국비지원...탑크리에듀(구로디지털단지역3번출구 2분거리)
1) The document describes a Spring Boot RESTful web service example that retrieves data from an Oracle table and returns it as a JSON response. It also returns a single record as an object mapped to JSON based on searching by name.
2) Jackson library and @RestController annotation are used to return the response as JSON instead of using JSP.
3) The name parameter is passed in the URL path instead of as a parameter, and is used to query the database and return the matching data as a JSON response.Keeping Spark on Track: Productionizing Spark for ETL
ETL is the first phase when building a big data processing platform. Data is available from various sources and formats, and transforming the data into a compact binary format (Parquet, ORC, etc.) allows Apache Spark to process it in the most efficient manner. This talk will discuss common issues and best practices for speeding up your ETL workflows, handling dirty data, and debugging tips for identifying errors.
Speakers: Kyle Pistor & Miklos Christine
This talk was originally presented at Spark Summit East 2017.
SAADATMAND_PYTHON
The Python script processes GPS data to visualize it in 3D space-time. It adds fields to the GPS point feature class for hour, minute, second values extracted from the date/time field. It calculates these values and additional time fields. The script then uses the fields to generate 3D line features representing the GPS track over time, for visualization in ArcScene.
Apps1
The document provides steps to develop various types of procedures, reports, interfaces, and loads in Oracle Applications. It outlines the key steps as: 1) develop the code/logic; 2) move files to server; 3) create concurrent executable; 4) create concurrent program; 5) attach program to request group; and 6) submit the program. The document also summarizes how to develop inbound and outbound interfaces, and provides examples of common tables and queries.
Do something in 5 with gas 7-email log
number 7 in do something useful with Google Apps script, covers how to search gmail for threads matching a topic and log recipients to a spreadsheet.
Recommended
Florence Spacex Final Presentation DS Capstone.pdf
Coursera IBM Applied Data Science Capstone SpaceX project final presentation
Github link for reference: https://github.com/florenceyyw/Applied-Data-Science-Capstone
IBM SpaceX Capstone Project
In this project, I will work in SpaceX company and try to predict the Falcon 9 first stage. It’s important to know if the rockets will land successfully or not because the failure will cost the company many resources.
Kafka Summit NYC 2017 - Singe Message Transforms are not the Transformations ...
Single message transformations allow lightweight modifications to individual messages as they are ingested or emitted by Kafka Connect connectors. Some key uses of single message transformations include data masking, event routing, event enhancement, and partitioning. They involve simple, message-at-a-time transformations configured through properties rather than writing complex code. Kafka Streams is better suited for more complex transformations like aggregations, joins, and windowing where the transformed data is stored back in Kafka.
#29.스프링프레임워크 & 마이바티스 (Spring Framework, MyBatis)_스프링프레임워크 강좌, 재직자환급교육,실업자국비지원...
#29.스프링프레임워크 & 마이바티스 (Spring Framework, MyBatis)_스프링프레임워크 강좌, 재직자환급교육,실업자국비지원...탑크리에듀(구로디지털단지역3번출구 2분거리)
1) The document describes a Spring Boot RESTful web service example that retrieves data from an Oracle table and returns it as a JSON response. It also returns a single record as an object mapped to JSON based on searching by name.
2) Jackson library and @RestController annotation are used to return the response as JSON instead of using JSP.
3) The name parameter is passed in the URL path instead of as a parameter, and is used to query the database and return the matching data as a JSON response.Keeping Spark on Track: Productionizing Spark for ETL
ETL is the first phase when building a big data processing platform. Data is available from various sources and formats, and transforming the data into a compact binary format (Parquet, ORC, etc.) allows Apache Spark to process it in the most efficient manner. This talk will discuss common issues and best practices for speeding up your ETL workflows, handling dirty data, and debugging tips for identifying errors.
Speakers: Kyle Pistor & Miklos Christine
This talk was originally presented at Spark Summit East 2017.
SAADATMAND_PYTHON
The Python script processes GPS data to visualize it in 3D space-time. It adds fields to the GPS point feature class for hour, minute, second values extracted from the date/time field. It calculates these values and additional time fields. The script then uses the fields to generate 3D line features representing the GPS track over time, for visualization in ArcScene.
Apps1
The document provides steps to develop various types of procedures, reports, interfaces, and loads in Oracle Applications. It outlines the key steps as: 1) develop the code/logic; 2) move files to server; 3) create concurrent executable; 4) create concurrent program; 5) attach program to request group; and 6) submit the program. The document also summarizes how to develop inbound and outbound interfaces, and provides examples of common tables and queries.
Do something in 5 with gas 7-email log
number 7 in do something useful with Google Apps script, covers how to search gmail for threads matching a topic and log recipients to a spreadsheet.
SQLite Techniques
The document discusses SQLite, including that it is a file-based, single-user, cross-platform SQL database engine. It provides information on SQLite tools like SQLite Manager and the sqlite3 command line utility. It also covers how to use the SQLite API in iOS/macOS applications, including opening a database connection, executing queries, and using prepared statements. Key aspects covered are getting the documents directory path, copying a default database on app startup, and the callback signature for query results.
Search Engine Building with Lucene and Solr (So Code Camp San Diego 2014)
Slides for my presentation at SoCal Code Camp, June 29, 2014
(http://www.socalcodecamp.com/socalcodecamp/session.aspx?sid=6337660f-37de-4d6e-a5bc-46ba54478e5e)
Data Source API in Spark
Video of the presentation can be seen here: https://www.youtube.com/watch?v=uxuLRiNoDio
The Data Source API in Spark is a convenient feature that enables developers to write libraries to connect to data stored in various sources with Spark. Equipped with the Data Source API, users can load/save data from/to different data formats and systems with minimal setup and configuration. In this talk, we introduce the Data Source API and the unified load/save functions built on top of it. Then, we show examples to demonstrate how to build a data source library.
Write a Java Class to Implement a Generic Linked ListYour list mus.pdf
Write a Java Class to Implement a Generic Linked List
Your list must be implemented as a singly-linked list of generic nodes, where each Node object
has two instance variables: an object of the “type variable” class, and a pointer to the next node
on the list.
Your class will contain separate methods to handle each of the operations read from a data file
(see II., below)
Your class will also override toString() to return the objects on the list in the order in which they
occur.
Write a Test Class for Your LinkedList Class
Your main method will read list operation instructions from a data file, until end-of-file and call
the appropriate LinkedList method to execute each one.
After each operation is executed, print out the operation and the updated list.
The data file to be used is on the class web site and the operations are:
APPEND X - Append object X to the end of the list
ADD N X - Insert object X as the new Nth element in the list, increasing the size of the list by 1
E.g. Suppose the list is:
head -> 1 -> 2 -> 3 -> 4->null
After ADD 3 7 it would be:
head -> 1 -> 2 -> 7 -> 3 -> 4->null
DELETE N – Remove the Nth object from the list
SWAP M N - Interchange the positions of the Mth and Nth
objects on the list
For credit, the two nodes must actually \"trade places\" in the list, and not merely swap their data
values
REVERSE - Reverse the order of the objects on the list
This must be done by reversing the order of the nodes themselves, rather than by swapping the
data stored
To get credit for your reverse() method, it must use either one of these 2 algorithms:
For each node on the list except the current “head”
node, delete the node and insert it as the new head
Use your swap() method
6. CLEAR – Clear the list (make it empty)
No credit will be given for programs that use any additional data structures – either from the Java
API or programmer defined -, other than your own LinkedList class
txt file:
Solution
//Java Program to Implement Singly Linked List
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/* Class Node */
class Nodes
{
protected Object data;
protected Nodes next;
/* Constructor */
public Nodes()
{
next = null;
data = null;
}
/* Constructor */
public Nodes(Object d,Nodes n)
{
data = d;
next = n;
}
/* Function to set link to next Node */
public void setLink(Nodes n)
{
next = n;
}
/* Function to set data to current Node */
public void setData(Object d)
{
data = d;
}
/* Function to get link to next node */
public Nodes getLink()
{
return next;
}
/* Function to get data from current Node */
public Object getData()
{
return data;
}
}
/* Class linkedList */
class linkList
{
protected Nodes start;
protected Nodes end ;
public int size ;
/* Constructor */
public linkList()
{
start = null;
end = null;
size = 0;
}
/* Function to check if list is empty */
public boolean isEmpty()
{
return start == null;
}
/* Function to get size of list */
public int getSize()
{
return .
SQLite Techniques
The document discusses techniques for using SQLite databases in iOS applications. Some key points covered include:
SQLite is a file-based, lightweight database that is well suited for mobile applications. The pure C API can be difficult to use directly, so it's best to abstract it away. The document reviews methods for opening and copying databases, executing queries using the SQLite API, and using prepared statements.
2017 02-07 - elastic & spark. building a search geo locator
Presentazione dell'evento EsInRome del 7 Febbraio 2017 - Integrazione Elasticsearch in architettura BigData e facilità di integrazione con Apache Spark.
2017 02-07 - elastic & spark. building a search geo locator
Using Elasticsearch in a BigData environment is very simple. In this talk, we analyse what's Big Data and we show how it is easy integrating ElasticSearch with Apache Spark
nodejs_at_a_glance.ppt
This document provides an overview of Node.js and how to build web applications with it. It discusses asynchronous and synchronous reading and writing of files using the fs module. It also covers creating HTTP servers and clients to handle network requests, as well as using common Node modules like net, os, and path. The document demonstrates building a basic web server with Express to handle GET and POST requests, and routing requests to different handler functions based on the request path and method.
A Standard Data Format for Computational Chemistry: CSX
The document discusses the development of a Common Standard for eXchange (CSX) to standardize the reporting of computational chemistry calculation results. CSX uses XML to capture calculation metadata, details about the molecular system studied, software and methods used, and calculated results in a structured format. This will allow results from different software packages to be more easily compared and facilitate sharing and reuse of computational chemistry data. Future plans include expanding the CSX schema and engaging the computational chemistry community to adopt the standard.
Slides
This document outlines a study on identifying classes in JavaScript code. It presents a technique called JSDeodorant that uses data flow analysis and function body analysis to identify class emulations. The approach was evaluated on several open source projects and found to have high precision and recall, outperforming an existing tool. An empirical study also found statistical differences in how classes are adapted across NodeJS, website, and library code. Future work could include identifying code smells and supporting class inheritance and modern JavaScript features.
Migrate database to Exadata using RMAN duplicate
Umair Mansoob discusses migrating a database from a Linux system to an Oracle Exadata system using RMAN duplicate. The key steps are:
1. Create a static local listener on the Exadata target and copy the password file.
2. Add TNS entries and test connections on source and target.
3. Create a pfile on the target and start it in nomount mode.
4. Run the RMAN duplicate command to copy the database, then optionally convert it to a RAC database and register it with CRS.
Spline 0.3 and Plans for 0.4
Overview of Spline 0.3 and plans for version 0.4 aimed at developers. Comparison of Spline and Hortonworks Atlas Connector.
Scylla Summit 2016: Analytics Show Time - Spark and Presto Powered by Scylla
Learn what Spark and Presto are, who uses them and why, how to use them with Scylla, and the awesome advantages your get if you do so.
Wso2 Scenarios Esb Webinar July 1st
The document describes three real-world integration scenarios using WSO2 ESB:
1) XML transformation and message augmentation using an XML transformation and database lookup to enrich messages.
2) A financial services use case of reading legacy flat files and integrating with JMS. It involves splitting, iterating, transforming, and sending messages.
3) The PushMePullYou scenario uses polling to integrate two services, involving task configuration, calling external services, splitting/transforming messages, and aggregating responses.
Sqlmap
A basic tutorial on using sqlmap on Kali Linux for sql injection.
The main focus being on comparison between manual and automated sql injection.
Some important parameters discussed and steps to be taken to discover vulnerabilities
By rushikesh kulkarni, president of Anonymous Club of BMSCE
03 form-data
This document discusses various techniques for handling form data submitted to servlets, including reading parameters, handling missing or malformed data, and filtering special characters.
It provides code examples of:
1) Reading individual and all parameters submitted via GET and POST.
2) Checking for missing parameters and using default values. It shows code for a resume posting site that uses default fonts/sizes if values are missing.
3) Filtering special HTML characters like < and > from parameter values before displaying them. It demonstrates a code sample servlet that properly filters values.
The document discusses strategies for handling missing or malformed data like using default values, redisplaying the form, and covering more advanced options using frameworks
Take a Trip Into the Forest: A Java Primer on Maps, Trees, and Collections
Wondering how to take advantage of Java and managed beans in XPages? To do this requires knowing how to store data in Java objects and a good understanding of maps, trees, lists, and sets. No, we're not talking about Google Maps or those big green things in forests, but different Java interfaces!
Come learn from Howard Greenberg of TLCC as he discusses different programming models to use when storing application configuration information, speeding up lookups to Domino data and feeding data to repeat and table controls. Learn how to build reports from different data sources. Plus, Howard will also look at working with dates and numbers in Java and Domino. Finally, he will review the Domino Java APIs and an alternative, the OpenNTF Domino API.
Environment Canada's Data Management Service
A brief history in TimeSeries data at Environment Canada. An Enterprise view of how FME can be integrated into departmental data management activities.
Maria Patterson - Building a community fountain around your data stream
1. The document discusses building a community around astronomical data streams using Apache Kafka for transport, Apache Avro for data formatting, and Apache Spark for filtering.
2. It provides examples of using these tools to prototype an alert stream, including mock data and filtering demonstrations.
3. The tools allow open access to large astronomical data streams in a scalable and flexible way for diverse creative uses.
一比一原版斯威本理工大学毕业证(swinburne毕业证)如何办理
原版一模一样【微信:741003700 】【斯威本理工大学毕业证(swinburne毕业证)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
More Related Content
Similar to Présentation sans titre.pptx
SQLite Techniques
The document discusses SQLite, including that it is a file-based, single-user, cross-platform SQL database engine. It provides information on SQLite tools like SQLite Manager and the sqlite3 command line utility. It also covers how to use the SQLite API in iOS/macOS applications, including opening a database connection, executing queries, and using prepared statements. Key aspects covered are getting the documents directory path, copying a default database on app startup, and the callback signature for query results.
Search Engine Building with Lucene and Solr (So Code Camp San Diego 2014)
Slides for my presentation at SoCal Code Camp, June 29, 2014
(http://www.socalcodecamp.com/socalcodecamp/session.aspx?sid=6337660f-37de-4d6e-a5bc-46ba54478e5e)
Data Source API in Spark
Video of the presentation can be seen here: https://www.youtube.com/watch?v=uxuLRiNoDio
The Data Source API in Spark is a convenient feature that enables developers to write libraries to connect to data stored in various sources with Spark. Equipped with the Data Source API, users can load/save data from/to different data formats and systems with minimal setup and configuration. In this talk, we introduce the Data Source API and the unified load/save functions built on top of it. Then, we show examples to demonstrate how to build a data source library.
Write a Java Class to Implement a Generic Linked ListYour list mus.pdf
Write a Java Class to Implement a Generic Linked List
Your list must be implemented as a singly-linked list of generic nodes, where each Node object
has two instance variables: an object of the “type variable” class, and a pointer to the next node
on the list.
Your class will contain separate methods to handle each of the operations read from a data file
(see II., below)
Your class will also override toString() to return the objects on the list in the order in which they
occur.
Write a Test Class for Your LinkedList Class
Your main method will read list operation instructions from a data file, until end-of-file and call
the appropriate LinkedList method to execute each one.
After each operation is executed, print out the operation and the updated list.
The data file to be used is on the class web site and the operations are:
APPEND X - Append object X to the end of the list
ADD N X - Insert object X as the new Nth element in the list, increasing the size of the list by 1
E.g. Suppose the list is:
head -> 1 -> 2 -> 3 -> 4->null
After ADD 3 7 it would be:
head -> 1 -> 2 -> 7 -> 3 -> 4->null
DELETE N – Remove the Nth object from the list
SWAP M N - Interchange the positions of the Mth and Nth
objects on the list
For credit, the two nodes must actually \"trade places\" in the list, and not merely swap their data
values
REVERSE - Reverse the order of the objects on the list
This must be done by reversing the order of the nodes themselves, rather than by swapping the
data stored
To get credit for your reverse() method, it must use either one of these 2 algorithms:
For each node on the list except the current “head”
node, delete the node and insert it as the new head
Use your swap() method
6. CLEAR – Clear the list (make it empty)
No credit will be given for programs that use any additional data structures – either from the Java
API or programmer defined -, other than your own LinkedList class
txt file:
Solution
//Java Program to Implement Singly Linked List
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/* Class Node */
class Nodes
{
protected Object data;
protected Nodes next;
/* Constructor */
public Nodes()
{
next = null;
data = null;
}
/* Constructor */
public Nodes(Object d,Nodes n)
{
data = d;
next = n;
}
/* Function to set link to next Node */
public void setLink(Nodes n)
{
next = n;
}
/* Function to set data to current Node */
public void setData(Object d)
{
data = d;
}
/* Function to get link to next node */
public Nodes getLink()
{
return next;
}
/* Function to get data from current Node */
public Object getData()
{
return data;
}
}
/* Class linkedList */
class linkList
{
protected Nodes start;
protected Nodes end ;
public int size ;
/* Constructor */
public linkList()
{
start = null;
end = null;
size = 0;
}
/* Function to check if list is empty */
public boolean isEmpty()
{
return start == null;
}
/* Function to get size of list */
public int getSize()
{
return .
SQLite Techniques
The document discusses techniques for using SQLite databases in iOS applications. Some key points covered include:
SQLite is a file-based, lightweight database that is well suited for mobile applications. The pure C API can be difficult to use directly, so it's best to abstract it away. The document reviews methods for opening and copying databases, executing queries using the SQLite API, and using prepared statements.
2017 02-07 - elastic & spark. building a search geo locator
Presentazione dell'evento EsInRome del 7 Febbraio 2017 - Integrazione Elasticsearch in architettura BigData e facilità di integrazione con Apache Spark.
2017 02-07 - elastic & spark. building a search geo locator
Using Elasticsearch in a BigData environment is very simple. In this talk, we analyse what's Big Data and we show how it is easy integrating ElasticSearch with Apache Spark
nodejs_at_a_glance.ppt
This document provides an overview of Node.js and how to build web applications with it. It discusses asynchronous and synchronous reading and writing of files using the fs module. It also covers creating HTTP servers and clients to handle network requests, as well as using common Node modules like net, os, and path. The document demonstrates building a basic web server with Express to handle GET and POST requests, and routing requests to different handler functions based on the request path and method.
A Standard Data Format for Computational Chemistry: CSX
The document discusses the development of a Common Standard for eXchange (CSX) to standardize the reporting of computational chemistry calculation results. CSX uses XML to capture calculation metadata, details about the molecular system studied, software and methods used, and calculated results in a structured format. This will allow results from different software packages to be more easily compared and facilitate sharing and reuse of computational chemistry data. Future plans include expanding the CSX schema and engaging the computational chemistry community to adopt the standard.
Slides
This document outlines a study on identifying classes in JavaScript code. It presents a technique called JSDeodorant that uses data flow analysis and function body analysis to identify class emulations. The approach was evaluated on several open source projects and found to have high precision and recall, outperforming an existing tool. An empirical study also found statistical differences in how classes are adapted across NodeJS, website, and library code. Future work could include identifying code smells and supporting class inheritance and modern JavaScript features.
Migrate database to Exadata using RMAN duplicate
Umair Mansoob discusses migrating a database from a Linux system to an Oracle Exadata system using RMAN duplicate. The key steps are:
1. Create a static local listener on the Exadata target and copy the password file.
2. Add TNS entries and test connections on source and target.
3. Create a pfile on the target and start it in nomount mode.
4. Run the RMAN duplicate command to copy the database, then optionally convert it to a RAC database and register it with CRS.
Spline 0.3 and Plans for 0.4
Overview of Spline 0.3 and plans for version 0.4 aimed at developers. Comparison of Spline and Hortonworks Atlas Connector.
Scylla Summit 2016: Analytics Show Time - Spark and Presto Powered by Scylla
Learn what Spark and Presto are, who uses them and why, how to use them with Scylla, and the awesome advantages your get if you do so.
Wso2 Scenarios Esb Webinar July 1st
The document describes three real-world integration scenarios using WSO2 ESB:
1) XML transformation and message augmentation using an XML transformation and database lookup to enrich messages.
2) A financial services use case of reading legacy flat files and integrating with JMS. It involves splitting, iterating, transforming, and sending messages.
3) The PushMePullYou scenario uses polling to integrate two services, involving task configuration, calling external services, splitting/transforming messages, and aggregating responses.
Sqlmap
A basic tutorial on using sqlmap on Kali Linux for sql injection.
The main focus being on comparison between manual and automated sql injection.
Some important parameters discussed and steps to be taken to discover vulnerabilities
By rushikesh kulkarni, president of Anonymous Club of BMSCE
03 form-data
This document discusses various techniques for handling form data submitted to servlets, including reading parameters, handling missing or malformed data, and filtering special characters.
It provides code examples of:
1) Reading individual and all parameters submitted via GET and POST.
2) Checking for missing parameters and using default values. It shows code for a resume posting site that uses default fonts/sizes if values are missing.
3) Filtering special HTML characters like < and > from parameter values before displaying them. It demonstrates a code sample servlet that properly filters values.
The document discusses strategies for handling missing or malformed data like using default values, redisplaying the form, and covering more advanced options using frameworks
Take a Trip Into the Forest: A Java Primer on Maps, Trees, and Collections
Wondering how to take advantage of Java and managed beans in XPages? To do this requires knowing how to store data in Java objects and a good understanding of maps, trees, lists, and sets. No, we're not talking about Google Maps or those big green things in forests, but different Java interfaces!
Come learn from Howard Greenberg of TLCC as he discusses different programming models to use when storing application configuration information, speeding up lookups to Domino data and feeding data to repeat and table controls. Learn how to build reports from different data sources. Plus, Howard will also look at working with dates and numbers in Java and Domino. Finally, he will review the Domino Java APIs and an alternative, the OpenNTF Domino API.
Environment Canada's Data Management Service
A brief history in TimeSeries data at Environment Canada. An Enterprise view of how FME can be integrated into departmental data management activities.
Maria Patterson - Building a community fountain around your data stream
1. The document discusses building a community around astronomical data streams using Apache Kafka for transport, Apache Avro for data formatting, and Apache Spark for filtering.
2. It provides examples of using these tools to prototype an alert stream, including mock data and filtering demonstrations.
3. The tools allow open access to large astronomical data streams in a scalable and flexible way for diverse creative uses.
Similar to Présentation sans titre.pptx (19)
Search Engine Building with Lucene and Solr (So Code Camp San Diego 2014)
Search Engine Building with Lucene and Solr (So Code Camp San Diego 2014)
Write a Java Class to Implement a Generic Linked ListYour list mus.pdf
Write a Java Class to Implement a Generic Linked ListYour list mus.pdf
2017 02-07 - elastic & spark. building a search geo locator
2017 02-07 - elastic & spark. building a search geo locator
2017 02-07 - elastic & spark. building a search geo locator
2017 02-07 - elastic & spark. building a search geo locator
A Standard Data Format for Computational Chemistry: CSX
A Standard Data Format for Computational Chemistry: CSX
Scylla Summit 2016: Analytics Show Time - Spark and Presto Powered by Scylla
Scylla Summit 2016: Analytics Show Time - Spark and Presto Powered by Scylla
Take a Trip Into the Forest: A Java Primer on Maps, Trees, and Collections
Take a Trip Into the Forest: A Java Primer on Maps, Trees, and Collections
Maria Patterson - Building a community fountain around your data stream
Maria Patterson - Building a community fountain around your data stream
Recently uploaded
一比一原版斯威本理工大学毕业证(swinburne毕业证)如何办理
原版一模一样【微信:741003700 】【斯威本理工大学毕业证(swinburne毕业证)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理斯威本理工大学毕业证(swinburne毕业证)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Bangalore ℂall Girl 000000 Bangalore Escorts Service
Bangalore ℂall Girl 000000 Bangalore Escorts Service
Discovering Digital Process Twins for What-if Analysis: a Process Mining Appr...
This webinar discusses the limitations of traditional approaches for business process simulation based on had-crafted model with restrictive assumptions. It shows how process mining techniques can be assembled together to discover high-fidelity digital twins of end-to-end processes from event data.
Call Girls Hyderabad (india) ☎️ +91-7426014248 Hyderabad Call Girl
Call Girls Hyderabad (india) ☎️ +91-7426014248 Hyderabad Call Girl
一比一原版马来西亚博特拉大学毕业证(upm毕业证)如何办理
原版一模一样【微信:741003700 】【马来西亚博特拉大学毕业证(upm毕业证)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理马来西亚博特拉大学毕业证(upm毕业证)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理马来西亚博特拉大学毕业证(upm毕业证)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理马来西亚博特拉大学毕业证(upm毕业证)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理马来西亚博特拉大学毕业证(upm毕业证)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
一比一原版加拿大麦吉尔大学毕业证(mcgill毕业证书)如何办理
原版一模一样【微信:741003700 】【加拿大麦吉尔大学毕业证(mcgill毕业证书)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理加拿大麦吉尔大学毕业证(mcgill毕业证书)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理加拿大麦吉尔大学毕业证(mcgill毕业证书)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理加拿大麦吉尔大学毕业证(mcgill毕业证书)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理加拿大麦吉尔大学毕业证(mcgill毕业证书)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Interview Methods - Marital and Family Therapy and Counselling - Psychology S...
A proprietary approach developed by bringing together the best of learning theories from Psychology, design principles from the world of visualization, and pedagogical methods from over a decade of training experience, that enables you to: Learn better, faster!
[VCOSA] Monthly Report - Cotton & Yarn Statistics May 2024
We are pleased to share with you the latest VCOSA statistical report on the cotton and yarn industry for the month of May 2024.
Starting from January 2024, the full weekly and monthly reports will only be available for free to VCOSA members. To access the complete weekly report with figures, charts, and detailed analysis of the cotton fiber market in the past week, interested parties are kindly requested to contact VCOSA to subscribe to the newsletter.
Do People Really Know Their Fertility Intentions? Correspondence between Sel...
Fertility intention data from surveys often serve as a crucial component in modeling fertility behaviors. Yet, the persistent gap between stated intentions and actual fertility decisions, coupled with the prevalence of uncertain responses, has cast doubt on the overall utility of intentions and sparked controversies about their nature. In this study, we use survey data from a representative sample of Dutch women. With the help of open-ended questions (OEQs) on fertility and Natural Language Processing (NLP) methods, we are able to conduct an in-depth analysis of fertility narratives. Specifically, we annotate the (expert) perceived fertility intentions of respondents and compare them to their self-reported intentions from the survey. Through this analysis, we aim to reveal the disparities between self-reported intentions and the narratives. Furthermore, by applying neural topic modeling methods, we could uncover which topics and characteristics are more prevalent among respondents who exhibit a significant discrepancy between their stated intentions and their probable future behavior, as reflected in their narratives.
一比一原版澳洲西澳大学毕业证(uwa毕业证书)如何办理
原版一模一样【微信:741003700 】【澳洲西澳大学毕业证(uwa毕业证书)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理澳洲西澳大学毕业证(uwa毕业证书)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理澳洲西澳大学毕业证(uwa毕业证书)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理澳洲西澳大学毕业证(uwa毕业证书)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理澳洲西澳大学毕业证(uwa毕业证书)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Call Girls Lucknow 0000000000 Independent Call Girl Service Lucknow
Call Girls Lucknow 0000000000 Independent Call Girl Service Lucknow
Senior Engineering Sample EM DOE - Sheet1.pdf
Sample Engineering Profiles from Product Companies DOE EM etc
一比一原版(曼大毕业证书)曼尼托巴大学毕业证如何办理
原版一模一样【微信:741003700 】【(曼大毕业证书)曼尼托巴大学毕业证成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理(曼大毕业证书)曼尼托巴大学毕业证【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理(曼大毕业证书)曼尼托巴大学毕业证【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理(曼大毕业证书)曼尼托巴大学毕业证【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理(曼大毕业证书)曼尼托巴大学毕业证【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Ahmedabad Call Girls 7339748667 With Free Home Delivery At Your Door
Ahmedabad Call Girls 7339748667 With Free Home Delivery At Your DoorRussian Escorts in Delhi 9711199171 with low rate Book online
Ahmedabad Call Girls 7339748667 With Free Home Delivery At Your DoorHealth care analysis using sentimental analysis
This presentation is about health care analysis using sentiment analysis .
*this is very useful to students who are doing project on sentiment analysis
*
Recently uploaded (20)
Namma-Kalvi-11th-Physics-Study-Material-Unit-1-EM-221086.pdf
Namma-Kalvi-11th-Physics-Study-Material-Unit-1-EM-221086.pdf
Bangalore ℂall Girl 000000 Bangalore Escorts Service
Bangalore ℂall Girl 000000 Bangalore Escorts Service
Discovering Digital Process Twins for What-if Analysis: a Process Mining Appr...
Discovering Digital Process Twins for What-if Analysis: a Process Mining Appr...
Call Girls Hyderabad (india) ☎️ +91-7426014248 Hyderabad Call Girl
Call Girls Hyderabad (india) ☎️ +91-7426014248 Hyderabad Call Girl
Senior Software Profiles Backend Sample - Sheet1.pdf
Senior Software Profiles Backend Sample - Sheet1.pdf
Interview Methods - Marital and Family Therapy and Counselling - Psychology S...
Interview Methods - Marital and Family Therapy and Counselling - Psychology S...
[VCOSA] Monthly Report - Cotton & Yarn Statistics May 2024
[VCOSA] Monthly Report - Cotton & Yarn Statistics May 2024
saps4hanaandsapanalyticswheretodowhat1565272000538.pdf
saps4hanaandsapanalyticswheretodowhat1565272000538.pdf
Do People Really Know Their Fertility Intentions? Correspondence between Sel...
Do People Really Know Their Fertility Intentions? Correspondence between Sel...
Call Girls Lucknow 0000000000 Independent Call Girl Service Lucknow
Call Girls Lucknow 0000000000 Independent Call Girl Service Lucknow
Ahmedabad Call Girls 7339748667 With Free Home Delivery At Your Door
Ahmedabad Call Girls 7339748667 With Free Home Delivery At Your Door
CAP Excel Formulas & Functions July - Copy (4).pdf
CAP Excel Formulas & Functions July - Copy (4).pdf
Présentation sans titre.pptx
- 1. Use SpaceX Rest API Get HTML response from wikipedia Return SpaceX data in Json Extract data using BeautifulSoup Normalize data into CSV file Normalize data into CSV file ready for data wrangling Space API Webscraping
- 2. 1-getting response from API 2-converting response to a .json file and turn it into a Pandas dataframe 3-Apply custom fonctions to clean data 4- Assign in list to dictionaries, and create a new dataframe 5- filter the new dataframe
- 3. 2-Create beautifulSoup object 3- Find table 4- extract all column names from the HTML table header 5-Create a data frame by parsing the launch HTML tables 1-Getting response from HTML
- 4. 2-Calculate the number of launches on each site 3- Calculate the number and occurrence of each orbit 4- Calculate the number and occurence of mission outcome per orbit type 5-Create a landing outcome label from Outcome column 1-Identify and calculate the percentage of the missing values in each attribute 6-Handle null values