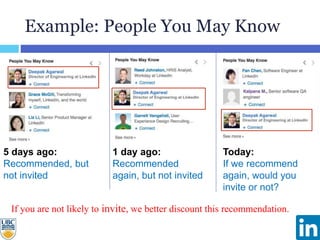
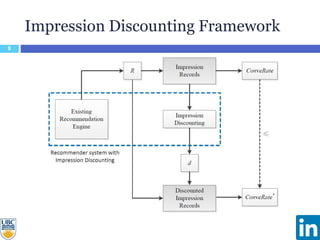
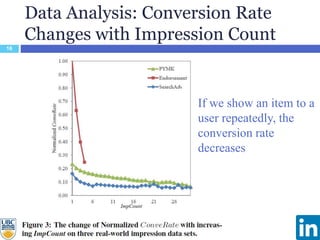
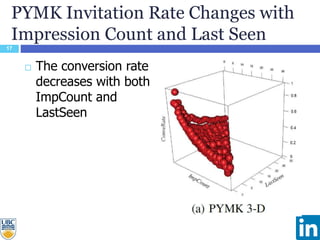
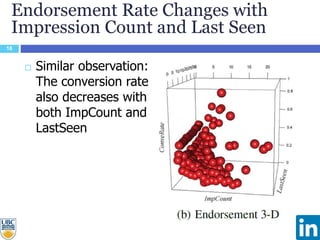
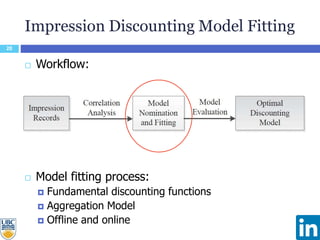
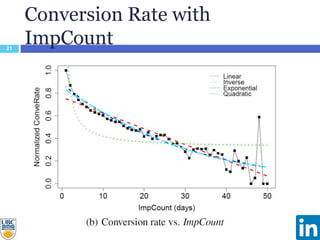
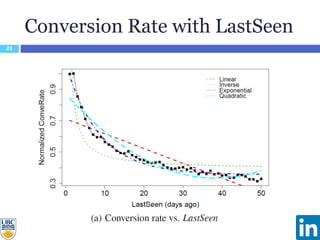
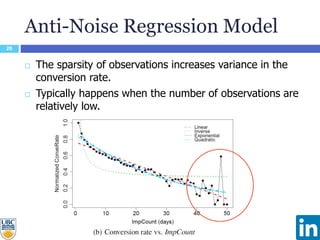
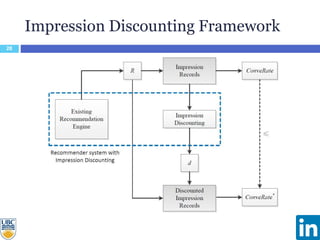
The document discusses a study presented at KDD 2014 on modeling impression discounting in large-scale recommender systems, particularly at LinkedIn. It defines impression discounting as the process of adjusting recommendations based on the likelihood of user engagement, focusing on parameters like frequency, recency, and user interaction. The analysis includes data from various datasets and evaluations of impression discounting models, concluding with insights into its effectiveness and applicability.