IBM Flash System 810 Eng
•
0 likes•1,578 views

independent review of IBM Flash System 810 (with IBM SVC)

Recommended
Recommended
More Related Content
What's hot
What's hot (19)
Viewers also liked
Viewers also liked (20)
Similar to IBM Flash System 810 Eng
Similar to IBM Flash System 810 Eng (20)
More from Oleg Korol
More from Oleg Korol (10)
Recently uploaded
Recently uploaded (20)
IBM Flash System 810 Eng
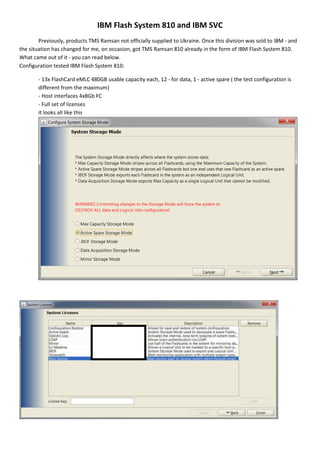
- 1. IBM FlashSystem 810 and IBM SVC Previously, products TMS Ramsan not officially supplied to Ukraine. Once this division was sold to IBM - and the situation has changed for me, on occasion, got TMS Ramsan 810 already in the form of IBM FlashSystem 810. What came out of it - you can read below. Configuration tested IBM FlashSystem 810: - 13x FlashCard eMLC 480GB usable capacity each, 12 - for data, 1 - active spare ( the test configuration is different from the maximum) - Host interfaces 4x8Gb FC - Full set of licenses it looks all like this
- 2. - In SPC-1 at the time of writing, there are no results IBM FlashSystem 810. A similar result is official (but fully fault-tolerant) IBM FlashSystem 820 в SPC-1– ~195K iops with Average Response Time 1,29ms. Carry out tests to determine the achievable performance indicators for IBM FlashSystem 810 in this configuration. And repeat them for situations where IBM FlashSystem 810 virtualized by IBM SVC, to determine - not whether SVC in such a situation the bottleneck? In a test environment part of IBM FlashSystem 810 was given directly (over FC-SAN) to the host, and the other part was presented to the host through a separate pool SVC (single io-group/two node CG8). The host was a dLPAR on IBM Power Systems 9117 -MMB with AIX 6.1 TL08 SP3 (in this release include native support for IBM FlashSystem 810 and it does not require extra ODM). From SVC and FlashSystem 810 was presented by host 16xLU, gathered at the stripe by AIX LVM. To organize the data file system was used JFS2 with inline log and mount options noatime, cio. Each of the filesystems (size to 2TB) was filled with data at > 80%. On IBM SVC all 16xLU were thin (IBM FlashSystem 810 has no similar technology). .
- 3. The first test is carried out for a multi-threaded load types - 100% Random, Read/Write = 80/20, by varying the size of the block (diagram 1, 2). IBM FlashSystem 810 connected to the host via SAN (without IBM SVC). • block 64KB/128KB reached the maximum bandwidth limited 4x8Gbit FC interfaces. • relatively low performance with a block size 512B and 2KB, due to the size of the default block used in the file system JFS2 (4KB) diagram 1 - IBM FlashSystem 810 100% Random, Read/Write= 80/20 250000 200000 IOPS 150000 100000 50000 0 FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 54303 54347 225278 191741 167754 89818 51661 25010 diagram 2 - IBM FlashSystem 810 average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB FlashSystem 810, write 512B 0.1 2KB 0.1 4KB 0.1 8KB 0.1 16KB 0.1 32KB 0.2 64KB 0.3 128KB 0.4 FlashSystem 810, read 0.2 0.2 0.3 0.5 0.8 1.5 3.5 8.2
- 4. Repeat the test for multi-threaded load types - 100% Random, Read/Write = 80/20, varying the size of the block, but presenting IBM FlashSystem 810 to the host through the IBM SVC (diagram 3, 4). As seen in the chart number of digits less than in the previous test. The reason was more than obvious - during the test was recorded maximum CPU utilization on both nodes SVC. Simultaneously with the reduction of number of iops increased response time. diagram 3 - IBM FlashSystem 810 over IBM SVC 100% Random, Read/Write= 80/20 250000 200000 IOPS 150000 100000 50000 0 SVC+FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 44444 44423 153889 135541 111212 68236 36558 18193 diagram 4 - IBM FlashSystem 810 over IBM SVC average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB SVC+FlashSystem 810, write 512B 0.1 2KB 0.1 4KB 0.5 8KB 0.5 16KB 0.5 32KB 0.4 64KB 0.5 128KB 0.6 SVC+FlashSystem 810, read 0.3 0.3 1.1 1.2 1.8 4 10 20
- 5. Repeat the test. Leaving unchanged the workload - 100% Random, Read/Write = 80/20. But now turn off caching on the SVC for the test volumes (Cache Mode Disabled ). As seen in the chart below (diagram 5, 6) - it has improved a bit in the result iops, but worsened the response time on large blocks. Again, the limiting factor was the CPU load on SVC nodes. diagram 5 - IBM FlashSystem 810 over IBM SVC 100% Random, Read/Write= 80/20 250000 200000 iops 150000 100000 50000 0 SVC (Cache disabled)+FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 45552 46684 191483 169890 133663 79913 40926 18821 diagram 6 - IBM FlashSystem 810 over IBM SVC average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB SVC (Cache disabled)+FlashSystem 810, write 0.1 0.1 0.2 0.2 0.2 0.5 1.2 2.2 SVC (Cache disabled)+FlashSystem 810, read 0.3 0.3 0.6 1 1.5 3.1 9 25
- 6. Compare previous data (diagram 7, 8). diagram 7 - iops 250000 200000 150000 100000 50000 0 512B 2KB 4KB SVC+FlashSystem 810 8KB 16KB 32KB 64KB SVC (Cache disabled)+FlashSystem 810 128KB FlashSystem 810 diagram 8 - average R/W latency, ms 25 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB FlashSystem 810, write SVC (Cache disabled)+FlashSystem 810, write SVC+FlashSystem 810, write FlashSystem 810, read SVC (Cache disabled)+FlashSystem 810, read SVC+FlashSystem 810, read
- 7. Dependence in the previous tests on the CPU load of the SVC iops reflected below diagram 9. diagram 9 - 100% Random, Read/Write= 80/20, block size=8KB SVC (Cache disabled)+FlashSystem 810 200 150 100 50 19 37 48 59 75 76 80 80 80 80 80 SVC CPU load % K IOPS 0 8 10 12 14 16 18 20 22 the number of concurrent streams -> 24 26 28
- 8. Results: As demonstrated above, the performance of a single IBM FlashSystem 810 is not even in full configuration outperforms single cluster IBM SVC. (IBM SVC + IBM FlashSystem, still faster than, for example, IBM Storwize V7000 with SSD). IBM SVC is available for a number of upgrades, in particular - the addition of a second CPU and another 4port FC HBA. In some IBM RedBooks, using IBM SVC and IBM FlashSystem together, have a recommendation upgrade IBM SVC nodes by setting the second FC HBA. But there is no recommendation to add a second processor. Why? After the above has been demonstrated that for this configuration is the bottleneck is CPU on SVC nodes. The reason is quite simple - the current code/firmware SVC can use extra CPU only (and exclusively) for Real-time Compression, because for general computing is not supported by more 4xCPU Core. Questions? Oleg Korol it-expert@ukr.net http://ua.linkedin.com/pub/oleg-korol/26/920/716